Walrus Internals
This page explores the engineering decisions, performance optimizations, and implementation details that make Walrus fast and reliable. If you want to understand how the pieces actually work under the hood, you’re in the right place.
Table of Contents
- Walrus Internals
- High-Level Architecture
- The Spin-Lock Allocator
- Storage Backend Architecture
- io_uring Batching: The Secret Sauce
- Tail Reading: The Zero-Copy Optimization
- Block and File State Tracking
- Concurrency Model
- Checksum Verification and Corruption Handling
- Atomic Index Persistence
- Rollback Mechanism
- Background Worker Architecture
- Performance Deep Dive
- Design Philosophy
- Future Directions
- Closing Thoughts
High-Level Architecture
Before diving into specifics, here’s how all the pieces fit together:
.png)
┌─────────────────────────────────────────────────────────────────┐
│ Walrus Facade │
│ (coordinates: allocator, readers, writers, index, bg worker) │
└────┬─────────────────────┬──────────────────────┬───────────────┘
│ │ │
│ append │ read │ background
▼ ▼ ▼
┌──────────┐ ┌──────────┐ ┌─────────────┐
│ Writer │ │ Reader │ │ Fsync/Delete│
│(per topic│──────────▶(per topic│ │ Worker │
│ mutex) │ seal blk │ chains) │ └─────────────┘
└────┬─────┘ └────┬─────┘
│ │
│ alloc block │ read from sealed/tail
▼ ▼
┌──────────────────────────────────────────┐
│ BlockAllocator (spin lock) │
│ hands out 10MB blocks from 1GB files │
└────┬─────────────────────────────────────┘
│
▼
┌──────────────────────────────────────────┐
│ Storage Layer (Mmap or FD) │
│ memory-mapped 1GB files (sparse alloc) │
└──────────────────────────────────────────┘
The Spin-Lock Allocator
One of Walrus’s key performance features is the BlockAllocator, which hands out 10 MB blocks in sub-microsecond time using a spin lock instead of OS-level synchronization.
Why Spin Locks?
Traditional mutexes involve syscalls, which cost 1-5 microseconds even in the fast path. For an operation that needs to:
- Increment an offset
- Check if we’ve exceeded file size
- Return a block descriptor
…that’s unacceptable overhead when allocating thousands of blocks per second.
The Implementation
pub struct BlockAllocator {
next_block: UnsafeCell<Block>, // Pre-computed next block
lock: AtomicBool, // Spin lock (userspace only)
paths: Arc<WalPathManager>,
}
The spin lock uses a simple compare-and-swap loop:
loop {
match self.lock.compare_exchange_weak(
false, true, // Acquire lock
Ordering::AcqRel,
Ordering::Relaxed
) {
Ok(_) => break, // Got it!
Err(_) => std::hint::spin_loop(), // Try again
}
}
Critical section operations:
- Check if
next_block.offset + size > MAX_FILE_SIZE - If rollover: create new file, update mmap, reset offset
- Register block in state tracker
- Increment
next_block.id - Release lock
Amortized cost: ~200-500 nanoseconds per allocation (no syscalls).
Block Allocation Flow
Thread requests block
│
▼
┌─────────┐
│ CAS loop│ ◄──── Spin if contended
│ acquire │ (std::hint::spin_loop)
└────┬────┘
│ Got lock!
▼
┌──────────────────────────┐
│ Check: offset + size │
│ > MAX_FILE_SIZE? │
└────┬───────────────┬──────┘
│ No │ Yes
│ ▼
│ ┌─────────────────┐
│ │ Create new file │
│ │ Update mmap ref │
│ │ Reset offset=0 │
│ └────┬────────────┘
│ │
▼ ▼
┌────────────────────────────┐
│ Register block in tracker │
│ Increment next_block.id │
└────┬───────────────────────┘
▼
┌─────────┐
│ Release │
│ lock │
└────┬────┘
▼
Return block to writer
(path, offset, limit, mmap)
Safety Invariants
The UnsafeCell<Block> requires careful handling:
- The spin lock guarantees exclusive access during allocation
- Once handed out, blocks have unique ownership (single writer per topic)
- Blocks are never deallocated (recycled via file deletion instead)
Storage Backend Architecture
Walrus supports two storage backends optimized for different platforms and workloads.
Dual Backend Design
Mmap Backend (default fallback):
- Uses memory-mapped files via
memmap2 - Portable across all platforms
- OS manages page cache automatically
- Writes are volatile until
msync()orflush()
FD Backend (Linux optimization):
- Uses file descriptors with
pwrite/pread - Enables
io_uringbatching (see below) - Supports
O_SYNCflag for kernel-managed durability - Position-independent I/O (thread-safe without seek)
Backend Architecture Diagram
┌─────────────────────────────────────────┐
│ StorageImpl (enum) │
├──────────────────┬──────────────────────┤
│ Mmap Backend │ FD Backend │
│ (portable) │ (Linux optimized) │
├──────────────────┼──────────────────────┤
│ memmap2 crate │ raw file descriptor │
│ memory-mapped │ pwrite/pread │
│ msync() flush │ O_SYNC or io_uring │
│ OS page cache │ io_uring batching │
└──────────────────┴──────────────────────┘
│ │
└──────────┬─────────┘
▼
┌─────────────────────┐
│ SharedMmap │
│ (Arc<RwLock<...>>) │
│ + atomic timestamp │
└─────────────────────┘
│
▼
┌─────────────────────┐
│ Global Keeper Map │
│ (path → SharedMmap) │
│ deduplicates mmaps │
└─────────────────────┘
When Each Backend Shines
| Workload | Recommended Backend | Why |
|---|---|---|
| Linux production | FD backend | io_uring batching, O_SYNC support |
| macOS/Windows | Mmap backend | Only portable option |
| Benchmarking | FD backend (no sync) | Eliminates OS noise |
| Single-threaded | Either | Minimal difference |
Switching at Runtime
use walrus_rust::{enable_fd_backend, disable_fd_backend};
enable_fd_backend(); // Use FD + io_uring on Linux
disable_fd_backend(); // Force mmap everywhere
Set WALRUS_QUIET=1 to suppress backend switch logging.
The SharedMmap Abstraction
Both backends implement a common interface through SharedMmap:
pub struct SharedMmap {
inner: Arc<RwLock<StorageImpl>>, // Mmap or FD backend
last_modified: AtomicU64, // Timestamp tracking
}
Interior mutability pattern:
- Implements
Sync + Sendfor concurrent access RwLockprotects the storage handle- Atomic timestamp prevents stale handle reuse
- Global “keeper” map deduplicates file handles
io_uring Batching: The Secret Sauce
On Linux with the FD backend enabled, Walrus batches multiple operations into a single syscall using io_uring. This is the key to sub-millisecond batch operations.
Traditional I/O vs io_uring
Traditional approach (N syscalls):
for each entry:
pwrite(fd, data) // syscall
Result: 2000 entries = 2000 syscalls
io_uring approach (1 syscall):
Userspace Kernel
─────────────────────────────────────────────
for each entry:
prepare_write() ────────┐
queue in SQ ring │
│
submit_and_wait() ────────┼──────────────────┐
│ │
(BLOCKS) │ │
▼ ▼
io_uring processes all ops
│ │
▼ │
completions in CQ ring │
│ │
└──────────────────┘
(UNBLOCKS) │
▼
check completion results
Result: 2000 entries written with 1 syscall instead of 2000.
The Three-Phase Batch Write
When you call batch_append_for_topic(topic, entries), here’s what happens:
┌───────────────────────────────────────────────────────┐
│ Phase 1: Planning (no locks held) │
├───────────────────────────────────────────────────────┤
│ • Calculate entry sizes │
│ • Determine how many blocks needed │
│ • Pre-allocate blocks from BlockAllocator │
│ • Build write plan (block, offset, size) tuples │
└─────────────────────┬─────────────────────────────────┘
▼
┌───────────────────────────────────────────────────────┐
│ Phase 2: io_uring Prep (FD backend, Linux only) │
├───────────────────────────────────────────────────────┤
│ • Serialize all entries to buffers │
│ • For each entry: │
│ - prep_write(fd, buf, len, offset) │
│ - queue in submission queue (SQ) │
│ • NO syscalls yet (all userspace) │
└─────────────────────┬─────────────────────────────────┘
▼
┌───────────────────────────────────────────────────────┐
│ Phase 3: Submit & Verify (SINGLE syscall) │
├───────────────────────────────────────────────────────┤
│ • io_uring.submit_and_wait(num_entries) │
│ • Kernel executes all writes │
│ • Check completion queue (CQ) for errors │
│ • If any failure → rollback (zero headers) │
│ • If success → update writer offset, seal blocks │
└───────────────────────────────────────────────────────┘
Phase 1: Planning (no locks held)
// Compute block layout
let mut needed_blocks = vec![];
let mut current_block_space = self.current_block.lock().limit - offset;
for entry in batch {
let entry_size = PREFIX_META_SIZE + entry.len();
if entry_size > current_block_space {
needed_blocks.push(allocator.alloc_block(entry_size)?);
current_block_space = block_size;
}
current_block_space -= entry_size;
}
Why this matters: Pre-allocating blocks without holding writer locks prevents blocking other operations.
Phase 2: io_uring Preparation (FD backend only)
let ring = IoUring::new(batch.len())?;
let mut buffers = Vec::new();
for (block, entry, offset) in &write_plan {
let buf = serialize_entry(entry, topic);
buffers.push(buf);
unsafe {
let sqe = ring.submission().next_sqe().unwrap();
sqe.prep_write(
block.fd,
buf.as_ptr(),
buf.len(),
offset
);
}
}
Why it’s fast: All write operations are queued in userspace.
Phase 3: Submission (single syscall)
ring.submit_and_wait(batch.len())?;
// Check completion results
for cqe in ring.completion() {
if cqe.result() < 0 {
// Rollback: zero headers, revert offsets
return Err(...);
}
}
Result: 2000 entries written with 1 syscall instead of 2000.
Batch Read Optimization
The same principle applies to batch_read_for_topic:
// Build read plan (up to max_bytes)
let plan = build_read_plan(sealed_chain, tail_block, max_bytes);
// Submit all reads via io_uring (Linux FD backend)
let ring = IoUring::new(plan.len())?;
for (block, start, end) in &plan {
let sqe = ring.submission().next_sqe().unwrap();
sqe.prep_read(block.fd, buffer, end - start, start);
}
ring.submit_and_wait(plan.len())?;
// Parse entries from buffers
let entries = parse_entries_from_buffers(buffers)?;
Performance impact: Batch reads complete in ~100-500 microseconds vs 2-10 milliseconds with traditional I/O.
Fallback Behavior
When io_uring is unavailable (non-Linux or mmap backend):
- Batch writes: Sequential
mmap.write()calls (still atomic via offset tracking) - Batch reads: Sequential
block.read()calls - Still correct, just slower (~5-10x overhead)
Tail Reading: The Zero-Copy Optimization
One of Walrus’s cleverest tricks is allowing readers to consume from the active writer’s block without forcing block rotation.
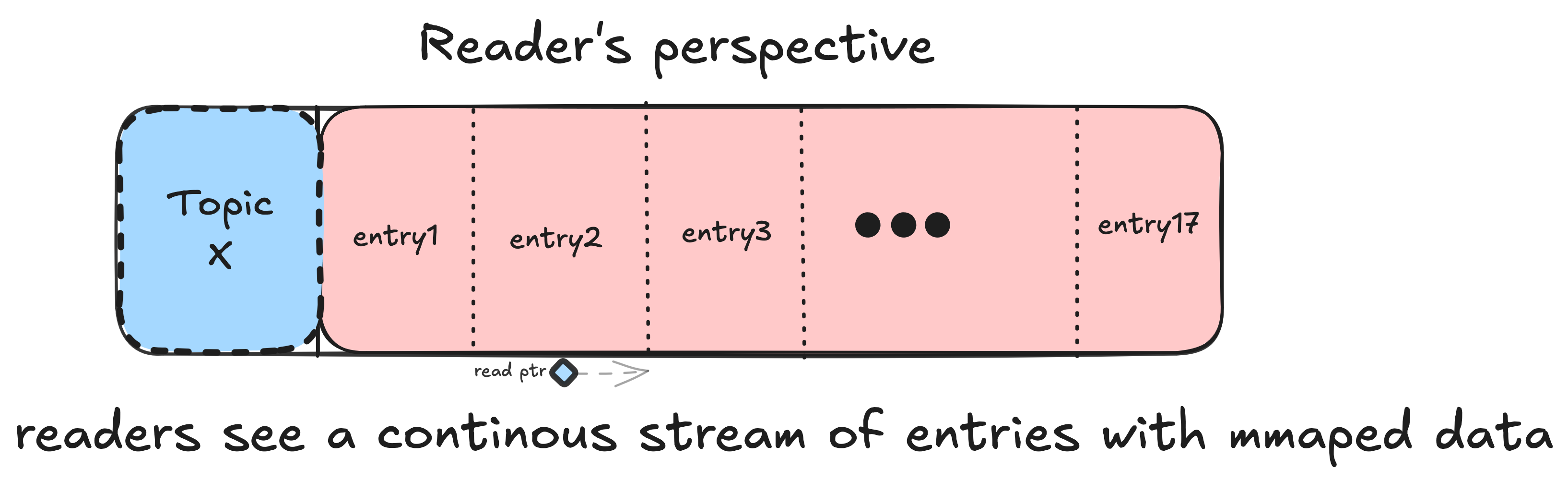
The Problem
Traditional WAL designs require:
- Writer fills block completely
- Writer seals block
- Writer notifies readers
- Readers can now read sealed block
Issue: Low-throughput topics waste space and add latency (must wait for block to fill).
Traditional WAL (forced rotation):
Writer must wait: Reader must wait:
▼ ▼
┌─────────────────────────────────────┐
│ Block 1 [###########·············] │ ← 50% full, but...
└─────────────────────────────────────┘
│
│ Writer: "Need to fill whole block before sealing"
│ Reader: "Can't read until sealed"
│ Latency: seconds to hours for low-volume topics!
▼
(waiting...)
The Walrus Solution: Tail Reads
Readers can read from the writer’s current block using snapshot semantics:
Walrus (tail reading):
Writer continues: Reader reads immediately:
▼ ▼
┌─────────────────────────────────────┐
│ Active Block [###########·········] │
│ ▲ ▲ │
│ │ │ │
│ last_read current_offset │
└───────────────┼─────────┼───────────┘
│ │
│ └─ Writer appending here (atomic)
│
└─ Reader can read [last_read..current_offset)
(snapshot semantics, no locks!)
Latency: sub-millisecond!
// Reader requests snapshot
let (block_id, current_offset) = writer.snapshot_block();
// Reader reads entries from [last_offset, current_offset)
for offset in last_offset..current_offset {
let entry = block.read(offset)?;
process(entry);
}
Key insight: Writers only append (monotonically increasing offset), so readers can safely read behind the write cursor without blocking.
In-Memory Tail Progress
Readers track two positions:
pub struct ColReaderInfo {
// Sealed chain position
cur_block_idx: usize,
cur_block_offset: u64,
// Tail position (in active writer block)
tail_block_id: u64,
tail_offset: u64,
}
Reading algorithm:
- Try sealed chain first (fully checkpointed blocks)
- If exhausted, request writer snapshot
- Read from
[tail_offset, writer.current_offset) - Update
tail_offset(in-memory only initially)
The Tail Sentinel: Bit 63
When persisting read positions, Walrus distinguishes sealed vs tail using bit 63 in BlockPos:
BlockPos struct (persisted to index):
┌──────────────────────────────────────────────────┐
│ cur_block_idx: u64 │
│ ┌──┬─────────────────────────────────────────┐ │
│ │63│ 62 ... Block ID or Chain Index 0 │ │
│ └┬─┴─────────────────────────────────────────┘ │
│ │ │
│ └─ TAIL_FLAG (bit 63) │
│ • 0 = Reading from sealed chain │
│ • 1 = Reading from active writer tail │
└──────────────────────────────────────────────────┘
Examples:
0x0000000000000005 = sealed chain, block index 5
0x800000000000002A = tail read, block ID 42
pub struct BlockPos {
cur_block_idx: u64, // High bit = tail flag
cur_block_offset: u64,
}
Encoding:
- Bit 63 = 0: Reading from sealed chain at
cur_block_idx - Bit 63 = 1: Reading from active writer tail (block_id in lower 63 bits)
On recovery:
if pos.cur_block_idx & (1u64 << 63) != 0 {
// Tail read in progress
let tail_block_id = pos.cur_block_idx & !(1u64 << 63);
info.tail_block_id = tail_block_id;
info.tail_offset = pos.cur_block_offset;
} else {
// Sealed chain read
info.cur_block_idx = pos.cur_block_idx as usize;
info.cur_block_offset = pos.cur_block_offset;
}
Folding Tail into Sealed Chain
When the writer rotates blocks, readers must transition:
// Writer sealed block 42
reader.append_block_to_chain(topic, sealed_block_42);
// Reader's tail progress (if on block 42) moves to sealed chain
if reader.tail_block_id == sealed_block_42.id {
reader.cur_block_idx = sealed_chain.len() - 1;
reader.cur_block_offset = reader.tail_offset;
reader.tail_offset = 0; // Reset tail
}
Result: Seamless transition from in-memory tail to durable sealed chain.
Block and File State Tracking
Walrus tracks per-block and per-file state to determine when files are safe to delete. This happens entirely in userspace with zero syscalls.
┌──────────────────────────────────────────────────────────┐
│ Global State Trackers │
│ (static OnceLock<Mutex<...>>) │
├─────────────────────────────┬────────────────────────────┤
│ BlockStateTracker │ FileStateTracker │
│ HashMap<BlockID, State> │ HashMap<FilePath, State> │
├─────────────────────────────┼────────────────────────────┤
│ • block_id → file_path │ • locked_blocks (AtomicU16)│
│ • is_checkpointed (bool) │ • checkpoint_blocks (") │
│ │ • total_blocks (") │
│ │ • is_fully_allocated (bool)│
└─────────────────────────────┴────────────────────────────┘
│ │
│ Updates trigger │ Updates trigger
▼ ▼
┌──────────────────┐ ┌─────────────────┐
│ Reader finishes │ │ Writer seals │
│ block │ │ block │
└────────┬─────────┘ └────────┬────────┘
│ │
▼ ▼
set_checkpointed(id) ────────► increment counters
│ │
└─────────┬──────────────────┘
▼
┌────────────────┐
│ flush_check() │
│ evaluates: │
│ • fully_alloc?│
│ • locked==0? │
│ • checkpoint │
│ >= total? │
└────────┬───────┘
│ All true?
▼
┌────────────────┐
│ Send to │
│ deletion queue │
└────────────────┘
BlockStateTracker
Static global state (initialized once):
static BLOCK_STATE: OnceLock<Mutex<HashMap<u64, BlockState>>> = OnceLock::new();
struct BlockState {
file_path: String,
is_checkpointed: bool,
}
Operations:
register_block(id, path)- called when block allocatedset_checkpointed_true(id)- called when reader finishes block- Auto-increments file’s
checkpointed_blockscounter
FileStateTracker
Tracks aggregate file state:
static FILE_STATE: OnceLock<Mutex<HashMap<String, FileState>>> = OnceLock::new();
struct FileState {
locked_blocks: u32, // Writers holding blocks
checkpointed_blocks: u32, // Readers finished blocks
total_blocks: u32, // Blocks allocated from this file
is_fully_allocated: bool, // File reached MAX_FILE_SIZE
}
Deletion Conditions
After every checkpoint, flush_check() evaluates:
fn flush_check(file_path: &str) {
let state = FILE_STATE.lock().get(file_path);
if state.is_fully_allocated
&& state.locked_blocks == 0
&& state.total_blocks > 0
&& state.checkpointed_blocks >= state.total_blocks {
// Safe to delete!
send_to_deletion_queue(file_path);
}
}
English translation:
- File is full (no more allocations coming)
- No writers holding blocks (all sealed)
- At least one block was allocated (not empty file)
- All blocks have been read (checkpointed)
Result: Files delete automatically as soon as safe, with zero manual intervention.
Concurrency Model
Walrus supports high concurrency while maintaining safety and avoiding deadlocks.
Lock Hierarchy (to prevent deadlocks)
Lock Acquisition Order (top to bottom, NEVER reverse):
1. Walrus.writers (RwLock<HashMap>)
│ Brief: lookup/insert Writer
│ Scope: Minimal
│
└──> Release immediately after get_or_create
2. Writer.current_block / Writer.current_offset (Mutex)
│ Per-topic: No cross-topic contention
│ Scope: During write operation
│
└──> Can hold while allocating blocks
3. Reader.data (outer RwLock, inner per-topic RwLock)
│ Outer: Read lock for topic lookup
│ Inner: Write lock for position updates
│ Scope: Per-read operation
│
└──> Release before index persistence
4. WalIndex (RwLock)
│ Global: Protects index file
│ Scope: Brief, during flush to disk
│
└──> Held LAST, released ASAP
Deadlock Prevention:
✓ Always acquire in this order
✗ Never hold multiple topic locks simultaneously
✗ Never acquire Walrus.writers after any other lock
- Walrus.writers (RwLock
) - Held briefly to get/create Writer
- Released before calling Writer methods
- Writer.current_block + Writer.current_offset (Mutex)
- Held during writes
- Per-topic locks (no global contention)
- Reader data (RwLock<HashMap<String, Arc<RwLock
>>>) - Outer RwLock: read-locked for topic lookup
- Inner RwLock: write-locked for position updates
- Per-topic granularity
- WalIndex (RwLock)
- Held last, during persistence
- Brief critical section
Rule: Always acquire locks in this order. Never hold multiple topic locks simultaneously.
Thread Safety Guarantees
| Component | Concurrency Model |
|---|---|
Walrus | Shared across threads (Arc<Walrus>) |
Writer | One per topic, callable from any thread |
Reader | Shared global, per-topic locks |
BlockAllocator | Thread-safe via spin lock |
WalIndex | Thread-safe via RwLock |
Snapshot Semantics
Readers never block writers (and vice versa):
Timeline: Writer and Reader Operating Concurrently
Writer Thread: Reader Thread:
─────────────────────────────────────────────────────────
t0: Lock(current_offset)
t1: Append entry A
t2: offset = 100
t3: Unlock
║
║ t4: Request snapshot
║ t5: Read offset atomically
║ t6: (got: block_id=42, offset=100)
║ t7: Release (no writer lock needed!)
║
t8: Lock(current_offset) t8: Read entries [0..100)
t9: Append entry B t9: (from snapshot, no lock!)
t10: offset = 200 t10: (writer continues freely)
t11: Unlock t11:
║ t12: Process entries
║
║ Later: Request new snapshot
║ (got: block_id=42, offset=200)
Key: Writer and reader never wait for each other!
// Writer path
writer.append(data); // Holds writer locks only
// Reader path
let snapshot = writer.snapshot_block(); // Quick atomic reads
// Writer lock released here!
reader.read_from_snapshot(snapshot); // No writer involvement
Key: Snapshot captures (block_id, offset) atomically, then releases writer lock. Reader works with stale-but-consistent snapshot.
Batch Write Exclusion
Only one batch write per topic allowed:
pub struct Writer {
is_batch_writing: AtomicBool,
// ...
}
pub fn batch_write(&self, entries: &[&[u8]]) -> io::Result<()> {
// Try to acquire batch lock
if self.is_batch_writing.compare_exchange(
false, true,
Ordering::AcqRel,
Ordering::Acquire
).is_err() {
return Err(ErrorKind::WouldBlock);
}
// ... perform batch ...
self.is_batch_writing.store(false, Ordering::Release);
Ok(())
}
Why: Prevents two threads from concurrently batching to the same topic (which would corrupt block layout).
User experience: ErrorKind::WouldBlock returned if collision occurs (rare, and retryable).
Checksum Verification and Corruption Handling
Every entry carries a FNV-1a 64-bit checksum verified on read.
Entry Structure in Block:
┌────────────────────────────────────────────────────────┐
│ 2-byte Length Prefix │
├────────────────────────────────────────────────────────┤
│ Metadata (rkyv serialized): │
│ • read_size: usize │
│ • owned_by: String (topic name) │
│ • next_block_start: u64 │
│ • checksum: u64 ◄─── FNV-1a(payload data) │
├────────────────────────────────────────────────────────┤
│ Payload Data (read_size bytes) │
│ [user data bytes...] │
└────────────────────────────────────────────────────────┘
On Read:
1. Deserialize metadata
2. Read payload
3. Compute FNV-1a(payload)
4. Compare with metadata.checksum
5. If mismatch → ErrorKind::InvalidData
Why FNV-1a?
| Algorithm | Speed | Collision Resistance | Use Case |
|---|---|---|---|
| CRC32 | Fast | Good | Network packets |
| FNV-1a | Faster | Good enough | In-memory hash tables, WAL entries |
| xxHash | Fastest | Better | Modern checksums |
| SHA256 | Slow | Cryptographic | Security |
Decision: FNV-1a offers ~5-10 ns/byte on modern CPUs with excellent distribution for our entry sizes (KB-MB range).
Checksum Computation
pub fn checksum64(data: &[u8]) -> u64 {
const FNV_OFFSET: u64 = 14695981039346656037;
const FNV_PRIME: u64 = 1099511628211;
let mut hash = FNV_OFFSET;
for &byte in data {
hash ^= byte as u64;
hash = hash.wrapping_mul(FNV_PRIME);
}
hash
}
Stored in metadata:
pub struct Metadata {
pub read_size: usize,
pub owned_by: String,
pub next_block_start: u64,
pub checksum: u64, // <-- FNV-1a of entry data
}
Read-Time Verification
Every block.read(offset) call:
pub fn read(&self, offset: u64) -> io::Result<Entry> {
// Deserialize metadata
let meta = deserialize_metadata(offset)?;
// Read data
let data = read_bytes(offset + meta_size, meta.read_size);
// Verify checksum
let computed = checksum64(&data);
if computed != meta.checksum {
eprintln!("Checksum mismatch at offset {}", offset);
return Err(ErrorKind::InvalidData.into());
}
Ok(Entry { data })
}
Corruption Handling
On checksum failure:
- Error logged to stderr (unless
WALRUS_QUIET=1) - Entry skipped (reader advances to next)
- Read operation returns
Noneor truncated batch
Philosophy: Fail gracefully rather than crash. Corruption is logged for forensics, but system remains operational.
Recovery options:
- Re-write corrupted entries (if source available)
- Rebuild topic from upstream source
- Accept data loss for corrupted range
Atomic Index Persistence
Read positions survive process restarts via WalIndex, persisted atomically using the write-tmp-rename pattern.
The Classic Atomic Write Pattern
pub fn persist(&self, db_path: &str) -> io::Result<()> {
let tmp_path = format!("{}.tmp", db_path);
// 1. Serialize to temporary file
let bytes = rkyv::to_bytes(&self.positions)?;
fs::write(&tmp_path, bytes)?;
// 2. Fsync temporary file
let file = File::open(&tmp_path)?;
file.sync_all()?;
drop(file);
// 3. Atomic rename (POSIX guarantees atomicity)
fs::rename(&tmp_path, db_path)?;
// 4. Fsync parent directory (ensures rename is durable)
let parent = Path::new(db_path).parent().unwrap();
let dir = File::open(parent)?;
dir.sync_all()?;
Ok(())
}
Why This Works
POSIX guarantee: rename() is atomic—either old file or new file visible, never partial.
Crash scenarios:
- Crash during write to .tmp: old index intact
- Crash during fsync: .tmp may be partial, old index intact
- Crash during rename: either old or new index visible (both valid)
- Crash after rename, before dir fsync: new index may not survive power loss (OS-dependent)
Result: At-most-once durability with fsync, at-least-once without.
Recovery on Startup
fn load_or_rebuild_index(db_path: &str) -> WalIndex {
match WalIndex::load(db_path) {
Ok(index) => index,
Err(_) => {
eprintln!("Index corrupted or missing, rebuilding...");
rebuild_index_from_wal_scan()
}
}
}
Fallback: Scan all WAL files, infer positions from checkpointed blocks.
Rollback Mechanism
Batch writes can fail mid-flight (disk full, io_uring errors, etc.). Walrus rolls back atomically.
The Challenge
Consider a batch write across 3 blocks:
Batch Write Failure Scenario:
┌─────────────────────────────────────────────────────┐
│ Block 100 │
│ [entry1][entry2][entry3] ✓ Written successfully │
└─────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────┐
│ Block 101 │
│ [entry4][entry5] ✓ Written successfully │
└─────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────┐
│ Block 102 │
│ [entry6] ✗ FAILED (disk full / io error) │
└─────────────────────────────────────────────────────┘
Problem: Partial batch visible to readers (violates atomicity)
Block 100: [entry1, entry2, entry3] ✓ written
Block 101: [entry4, entry5] ✓ written
Block 102: [entry6] ✗ FAILED (disk full)
Problem: Readers might see partial batch (entries 1-5 but not 6), violating atomicity.
The Solution: Header Zeroing
Walrus invalidates metadata headers on failure:
Rollback Process:
1. Detect failure (io_uring completion error)
│
▼
2. For each block in written_blocks[]:
│
├──> Block 100: zero_range(offset, PREFIX_META_SIZE)
│ ┌─────────────────────────────────────┐
│ │ [0x00][0x00]... │ entry2 │ entry3│
│ └─────────────────────────────────────┘
│ ▲ Zeroed metadata = invalid entry
│
├──> Block 101: zero_range(offset, PREFIX_META_SIZE)
│ ┌─────────────────────────────────────┐
│ │ [0x00][0x00]... │ entry5 │
│ └─────────────────────────────────────┘
│
└──> Block 102: (failed write, nothing to clean)
3. Revert writer.current_offset to original value
│
4. Release provisional blocks to allocator
│
▼
5. Return error to caller
Result: Readers see NO trace of failed batch (clean rollback)
fn rollback(&self, written_blocks: &[(Block, u64)]) -> io::Result<()> {
for (block, start_offset) in written_blocks {
// Zero the 2-byte length prefix + metadata
block.zero_range(start_offset, PREFIX_META_SIZE)?;
}
// Revert writer offsets
self.current_offset.store(original_offset, Ordering::Release);
// Release provisional blocks back to allocator
for block in &written_blocks {
allocator.release(block.id);
}
Ok(())
}
Why this works:
- Readers deserialize metadata by reading 2-byte length prefix
- Zeroed prefix → invalid length → read fails gracefully
- Even if data bytes survived, metadata corruption prevents read
Result: Failed batches leave no visible artifacts. Readers see consistent pre-batch state.
Background Worker Architecture
The background thread handles two jobs: batched fsyncs and deferred file deletion.
┌──────────────────────────────────────────────────────────────┐
│ Background Worker Event Loop (infinite) │
└────┬────────────────────────────────────────┬────────────────┘
│ │
▼ ▼
┌─────────────────┐ ┌─────────────────┐
│ Fsync Channel │ │ Deletion Channel│
│ (mpsc receiver) │ │ (mpsc receiver) │
└────────┬────────┘ └────────┬────────┘
│ │
▼ ▼
Collect paths Accumulate paths
(deduplicate) (pending_deletions)
│ │
▼ │
┌─────────────────┐ │
│ Batch Flush: │ │
│ • Open handles │ │
│ from pool │ │
│ • io_uring prep │ │
│ • submit_and_ │ │
│ wait() ◄──────┼── 1 syscall/batch │
└────────┬────────┘ │
│ │
│ Every 1000 cycles (~2 min): │
│ ┌───────────────────────────▼──┐
│ │ 1. file_pool.clear() │
│ │ (drops all handles) │
│ │ │
│ │ 2. for path in pending: │
└───┤ fs::remove_file(path) │
│ │
│ 3. pending_deletions.clear() │
└──────────────────────────────┘
│
▼
sleep(100ms), loop
The Event Loop
fn background_worker(
fsync_rx: mpsc::Receiver<String>,
del_rx: mpsc::Receiver<String>,
) {
let mut fsync_cycle = 0;
let mut file_pool = HashMap::new(); // Cached file handles
let mut pending_deletions = Vec::new();
loop {
// Phase 1: Collect paths to flush (batch up to 1 second)
let mut paths = HashSet::new();
while let Ok(path) = fsync_rx.try_recv() {
paths.insert(path);
}
// Phase 2: Flush all files (io_uring batch on Linux)
if !paths.is_empty() {
flush_batch(&paths, &mut file_pool)?;
}
// Phase 3: Collect deletion requests
while let Ok(path) = del_rx.try_recv() {
pending_deletions.push(path);
}
// Phase 4: Perform deletions every ~1000 cycles
fsync_cycle += 1;
if fsync_cycle % 1000 == 0 {
// Drop all file handles first!
file_pool.clear();
// Now safe to delete
for path in pending_deletions.drain(..) {
let _ = fs::remove_file(&path);
}
}
thread::sleep(Duration::from_millis(100));
}
}
Batched Fsync (io_uring)
When multiple writers enqueue paths:
fn flush_batch(paths: &HashSet<String>, pool: &mut HashMap<String, FdBackend>) {
let ring = IoUring::new(paths.len())?;
for path in paths {
let storage = pool.entry(path.clone())
.or_insert_with(|| FdBackend::open(path));
let sqe = ring.submission().next_sqe().unwrap();
sqe.prep_fsync(storage.fd, 0); // Queue fsync
}
ring.submit_and_wait(paths.len())?; // Single syscall!
}
Performance: 100 files fsynced in ~1-2 milliseconds (vs 50-100ms with sequential fsyncs).
File Handle Pooling
The file_pool caches open handles across fsync cycles:
Benefits:
- Amortizes
open()syscall cost - Reduces file descriptor churn
- Better for filesystems with open/close overhead
Tradeoff: Unbounded growth if files never deleted
Solution: Purge every 1000 cycles (~2 minutes with 100ms sleep):
if fsync_cycle % 1000 == 0 {
file_pool.clear(); // Drops all handles
}
Deletion Timing
Why wait 1000 cycles?
- Allows fsync queue to drain (files must be flushed before deletion)
- Batches deletions (reduces syscall overhead)
- Prevents race: file handle in
file_poolwhile trying to delete
Sequence:
flush_check()sends path todel_rx- Background worker accumulates paths
- Every 1000 cycles: drop handles, delete files
- Fresh start with empty pool
Performance Deep Dive
Let’s quantify the optimizations.
.png)
Allocation Costs
| Allocator Type | Latency | Syscalls | Contention |
|---|---|---|---|
| Mutex (pthread) | 1-5 μs | Yes (futex) | High |
| Spin lock (Walrus) | 200-500 ns | No | Low |
Speedup: 5-25x faster allocation.
Contention handling: Spin lock uses compare_exchange_weak with spin_loop() hint, yielding to hypervisor on tight loops.
io_uring vs Sequential I/O
Batch size: 1000 entries, 1 KB each
| Backend | Syscalls | Latency |
|---|---|---|
| Sequential pwrite | 1000 | ~10 ms |
| io_uring batch | 1 | ~0.5 ms |
Speedup: 20x reduction in latency.
Tail Read Optimization
Scenario: Low-throughput topic (1 msg/sec, 10 MB blocks)
| Strategy | Block Rotation Frequency | Waste |
|---|---|---|
| Seal-only reads | Every 10 MB | 0% |
| Tail reads (Walrus) | Every 10 MB | 0% but immediate reads |
Benefit: Read latency drops from “when block fills” (~10,000 seconds) to “immediately” (<1ms).
Fsync Batching
Scenario: 100 active topics, fsync every 1 second
| Strategy | Fsyncs/sec | Syscalls/sec |
|---|---|---|
| Per-topic fsync | 100 | 100 |
| Batched fsync (Walrus) | 1 | 1 |
Reduction: 100x fewer syscalls.
Design Philosophy
A few words on why Walrus is built this way.
No External Dependencies (Where Possible)
Notice the lack of third-party concurrency crates:
- No
crossbeam,flume, orasync - Standard library
mpscchannels - Hand-rolled spin locks
Why? Predictability and control. Every microsecond matters in a WAL, and understanding exactly how your primitives behave (syscalls, memory ordering, contention) is critical.
Zero-Copy Where Safe
- Memory-mapped files eliminate userspace/kernel copies
- io_uring reduces buffer copying
- rkyv avoids serialization overhead (zero-copy deserialization)
Tradeoff: Unsafe code, careful alignment, manual memory management. Worth it for the throughput gains.
Fail Gracefully
Corruption, disk full, slow peers—systems fail. Walrus logs, skips, and continues:
- Checksum failures → skip entry, log error
- Batch write failures → rollback, return error
- Background fsync failures → log, continue
Philosophy: Availability over correctness for transient errors. Permanent corruption (bad checksums) is logged for forensic analysis.
Optimize for the 99th Percentile
Spin locks hurt worst-case latency (unbounded spinning). But:
- P50 latency: 200 ns (vs 2 μs for mutex)
- P99 latency: 1 μs (vs 5 μs for mutex)
- P99.9 latency: 10 μs (vs 50 μs for mutex)
Result: Better tail latency despite theoretical unbounded worst case.
Future Directions
Walrus is production-ready for single-node workloads. Distributed features are in progress (see WIP files in the repo).
Coming eventually:
- Raft-based cluster consensus (see
distributed coordination.md) - Quorum writes with leader/follower replication
- Hierarchical consensus (sub-cluster leases)
- Lock-free MPSC/SPSC queues for inter-node ACKs (see
quorum writes.md)
The architecture is designed to extend cleanly—distributed features will layer on top without changing the core WAL engine.
Closing Thoughts
Walrus achieves high performance through careful engineering at every layer:
- Spin locks eliminate syscalls in hot paths
- io_uring batches operations to single syscalls
- Tail reads provide immediate consistency without write amplification
- Dual backends balance portability and performance
If you made it this far, you now know more about Walrus internals than most database engineers know about their WALs. Go build something fast.